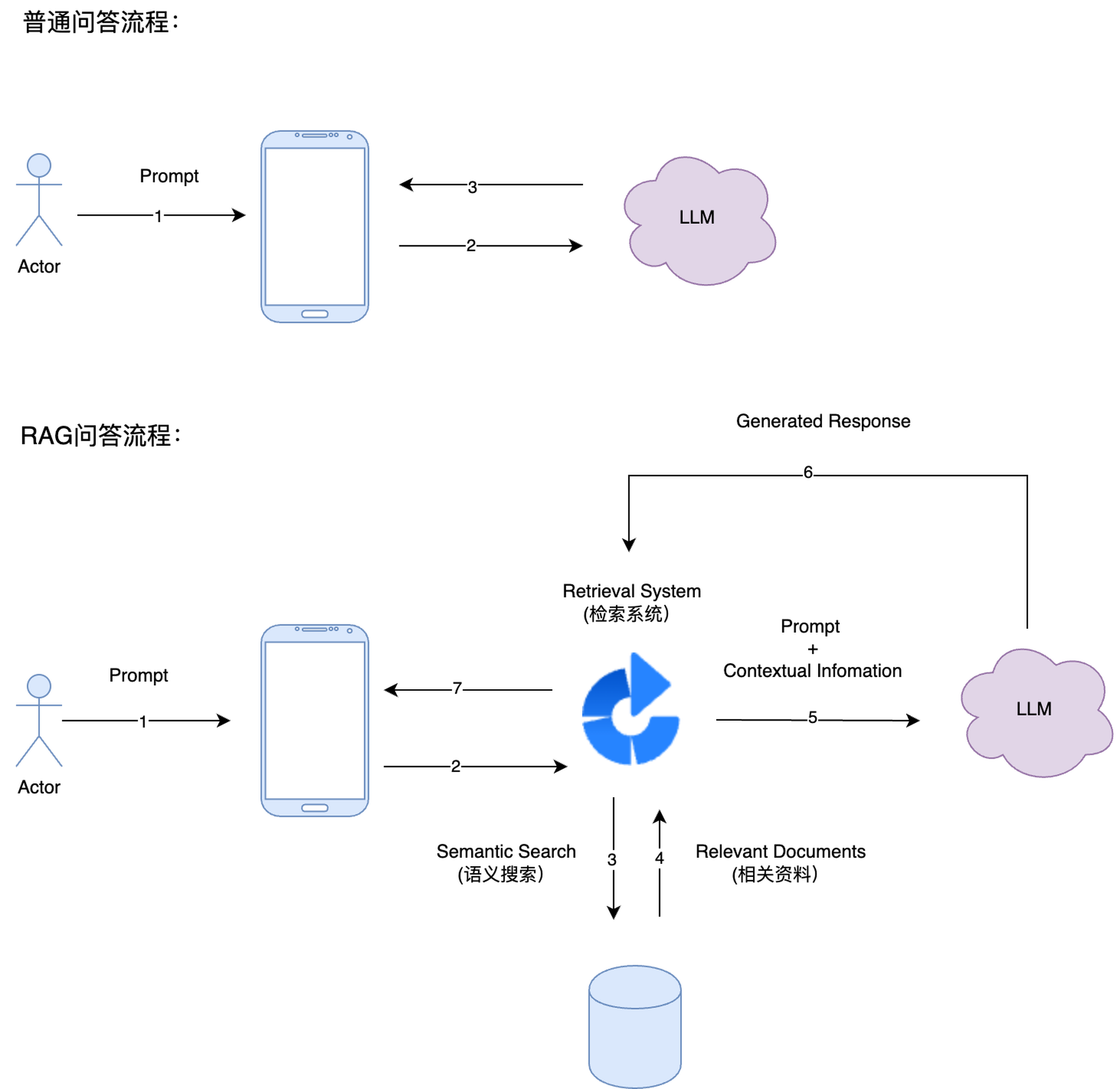
一、RAG 基础概念 1. 什么是 RAG?
定义 :检索增强生成(Retrieval-Augmented Generation)通过结合外部知识检索与生成模型,提升回答的准确性和事实性,解决大模型幻觉问题。
核心流程 :
检索 :从外部知识库(如向量数据库、知识图谱)中查找相关文档;
生成 :将检索结果作为上下文输入生成模型(如 GPT-4),生成最终回答。
2. 为什么需要 RAG?
二、RAG 的工作流程
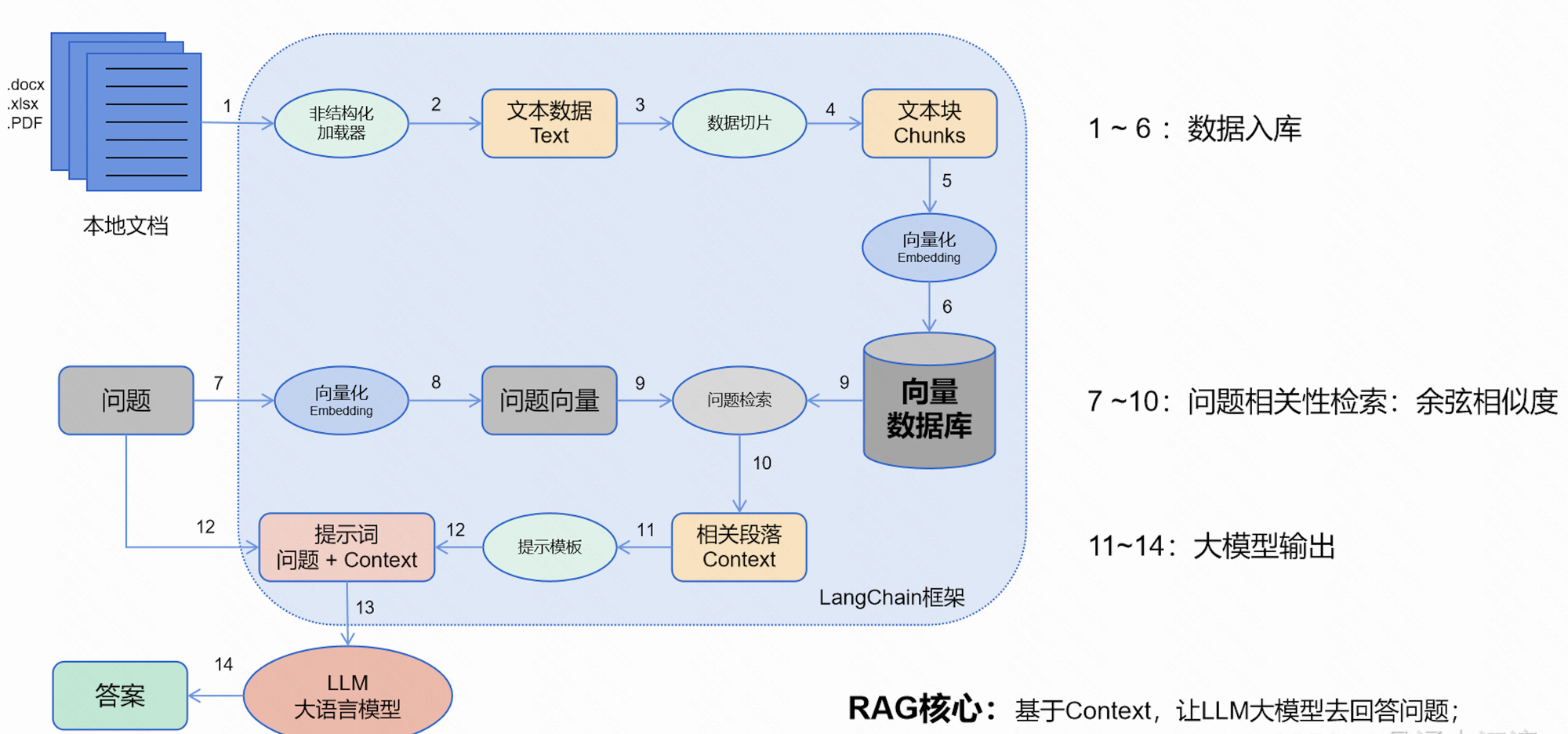
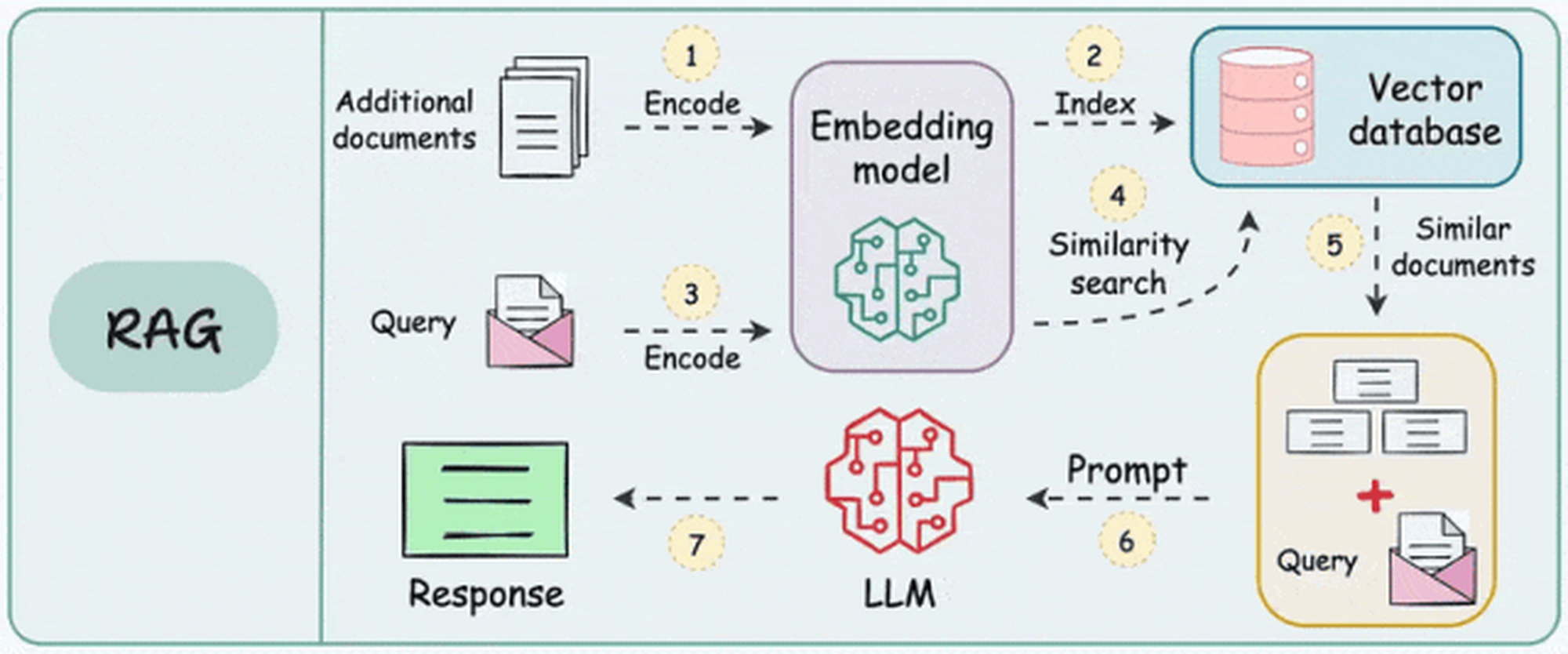
整体流程图
(图片来源 RAG 流程 )
待查找的资料(内部文档、数据库等资料)存入向量数据库
在数据库中查询最符合问题的资料
将资料和问题,一起交给大模型生成答案
召回符合用户预期的资料内容,合并问题,一起交给大模型,生成合理的答案。
详细解释 非结构化加载
上传的文档类型有 docs、PDF、数据库、xlsx 等,需要借助不同的文档加载器,将内部的内容提取出来
数据切片
在向量化的时候,输入的 token 数量是有限制的,通常的 500token 左右(也有专门长文本的 Embedding 模型), 我们从文档中召回内容的时候,也是以当前切割单元作为召回的基本单位
1 2 3 4 5 6 7 不同的 Embedding 模型对文本块长度的支持能力不同。比如,BERT 及其变体通常支持最多 512 个tokens,处理长文本时则需要将文本分成更小的块,意味着需要更加精细化的分块策略。而 Jina AI 的 Embedding 模型和 bge-m3 模型则支持 8K 的 tokens 输入,适合处理长文本块。通用 Embedding 模型在特定垂直领域(如医学、法律和金融等)可能不如专用模型有效。这些领域通常需要专门训练 Embedding 模型来捕捉特定的专业术语和语境。为特定业务需求优化的 Embedding 模型能够显著提升检索和生成的质量。例如,通过结合向量检索和重排序(reranking)技术,可以进一步优化结果。 //1. 不同的 Embedding 模型对文本块长度的支持能力不同 //2. 比如,BERT 及其变体通常支持最多 512 个tokens,处理长文本时则需要将文本分成更小的块,意味着需要更加精细化的分块策略 //3. 而 Jina AI 的 Embedding 模型和 bge-m3 模型则支持 8K 的 tokens 输入,适合处理长文本块。通用 Embedding 模型在特定垂直领域(如医学、法律和金融等)可能不如专用模型有效 //4. 这些领域通常需要专门训练 Embedding 模型来捕捉特定的专业术语和语境 //5. 为特定业务需求优化的 Embedding 模型能够显著提升检索和生成的质量。例如,通过结合向量检索和重排序(reranking)技术,可以进一步优化结果。
不同的数据切片方式,对召回有着关键的影响,不同领域,不同场景切片方案也不一样
方案一: 固定大小分块
(图片来源 RAG 中的 5 种文档切分策略 )
按预定义的字符数、单词数或 Token 数量对文本进行切分,同时保留一定的重叠部分。
这种方法实现简单,但可能会将句子截断,从而导致信息分散在不同的块中。
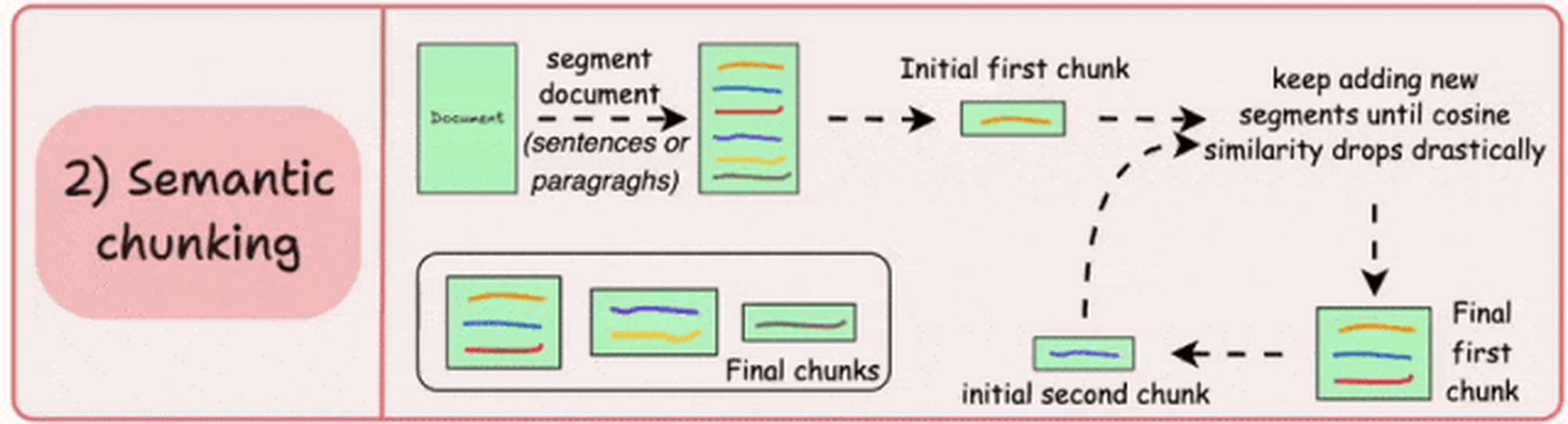
方案二:语义分块
(图片来源 RAG 中的 5 种文档切分策略 )
使用 NLP 模型(如 BERT、Sentence-BERT、RoBERTa)计算文本中句子或段落的语义嵌入(Embedding),通过向量相似度(如余弦相似度)检测语义连贯性变化点。若相邻段落的相似度低于阈值,则视为分块边界。
优势
保留上下文完整性
避免固定长度分块导致的上下文断裂(如拆散核心论点),提升检索内容的相关性。
提升检索精度
语义连贯的分块更可能匹配用户查询意图,减少噪声干扰。
局限性
计算成本高
语义分析依赖深度学习模型,处理长文档时可能增加延迟和资源消耗。
依赖模型质量
若语义模型在特定领域(如法律、医学)表现不佳,分块准确性会下降。
处理复杂文本的挑战
对多语言、口语化或非结构化文本(如社交媒体内容)的分块效果可能不稳定。
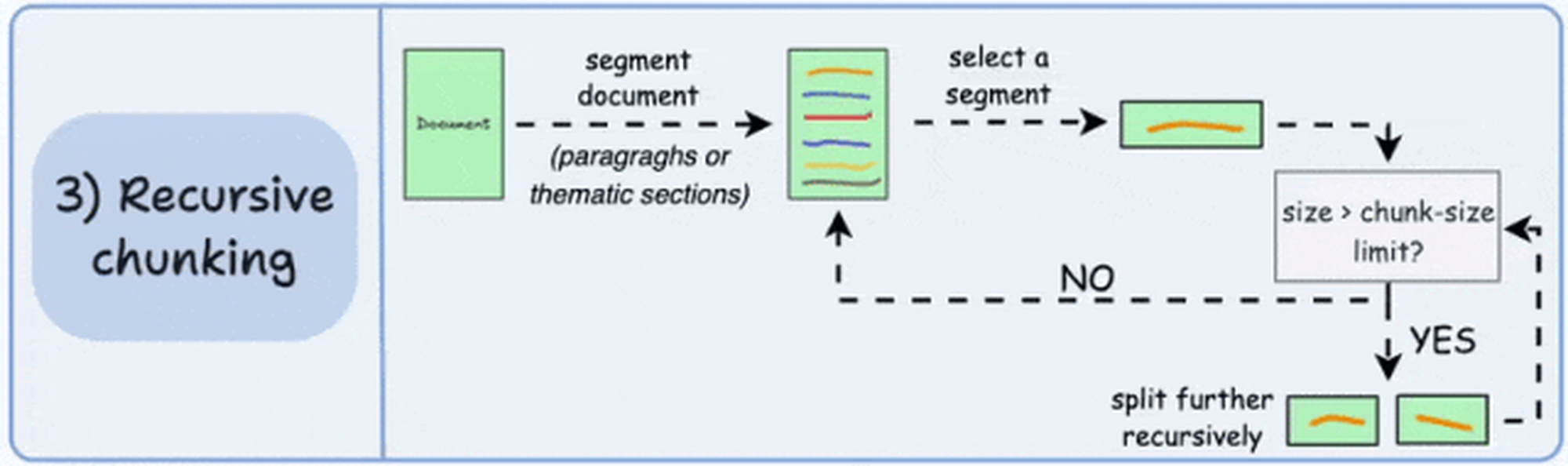
方案三:递归分块
(图片来源 RAG 中的 5 种文档切分策略 )
基于内在分隔符(如段落或章节)进行分块。
如果某个块的大小超过限制,则将其进一步分割为更小的块。
这种方法能够保持语言的自然流畅性。
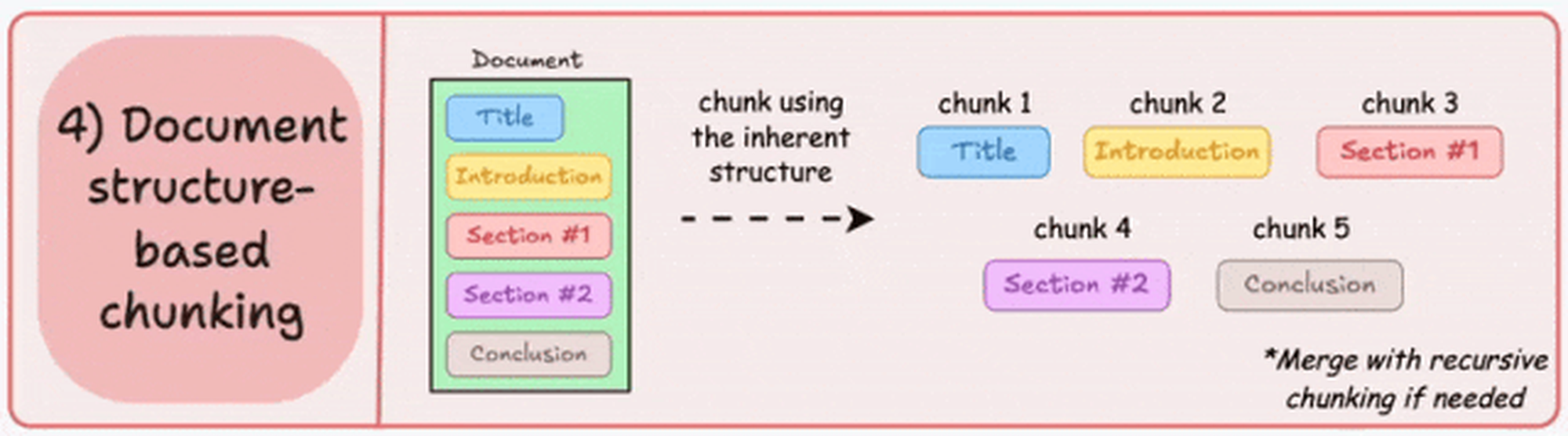
方案四:基于文档结构的分块
(图片来源 RAG 中的 5 种文档切分策略 )
利用文档的内在结构(如标题、章节或段落)进行分块。
这种方法能够保持文档的自然结构,但前提是文档具有清晰的结构。
方案五:基于 LLM 的分块
(图片来源 RAG 中的 5 种文档切分策略 )
存储和查询
向量化(Vectorization)
向量化是将文本(如单词、句子或文档)转换为数值向量(即嵌入向量)的过程。
嵌入环节的目标是将文本转换为高维向量,使语义相似的文本在向量空间中距离更近。
索引(Indexing)
索引是构建高效数据结构以存储和检索向量化数据的过程。在 RAG 中,通常使用向量索引(如 FAISS、Annoy)加速相似性搜索
3.1 向量化 (嵌入): 流程:
Embedding(嵌入): 也就是向量化,是有专门的模型来处理的,使用预训练模型(如 BERT、Sentence-BERT、RoBERTa)生成文本的向量表示 (https://ollama.com/search )
示例流程 :
输入文本:“什么是机器学习?”
通过 BERT 模型生成一个 768 维的向量(如 [0.23, -0.45, …, 0.67])。
(向量的维度越高,越精确,但是消耗的计算资源越大)
相似度计算:
(图片来源 Embedding 模型的选择和微调 )
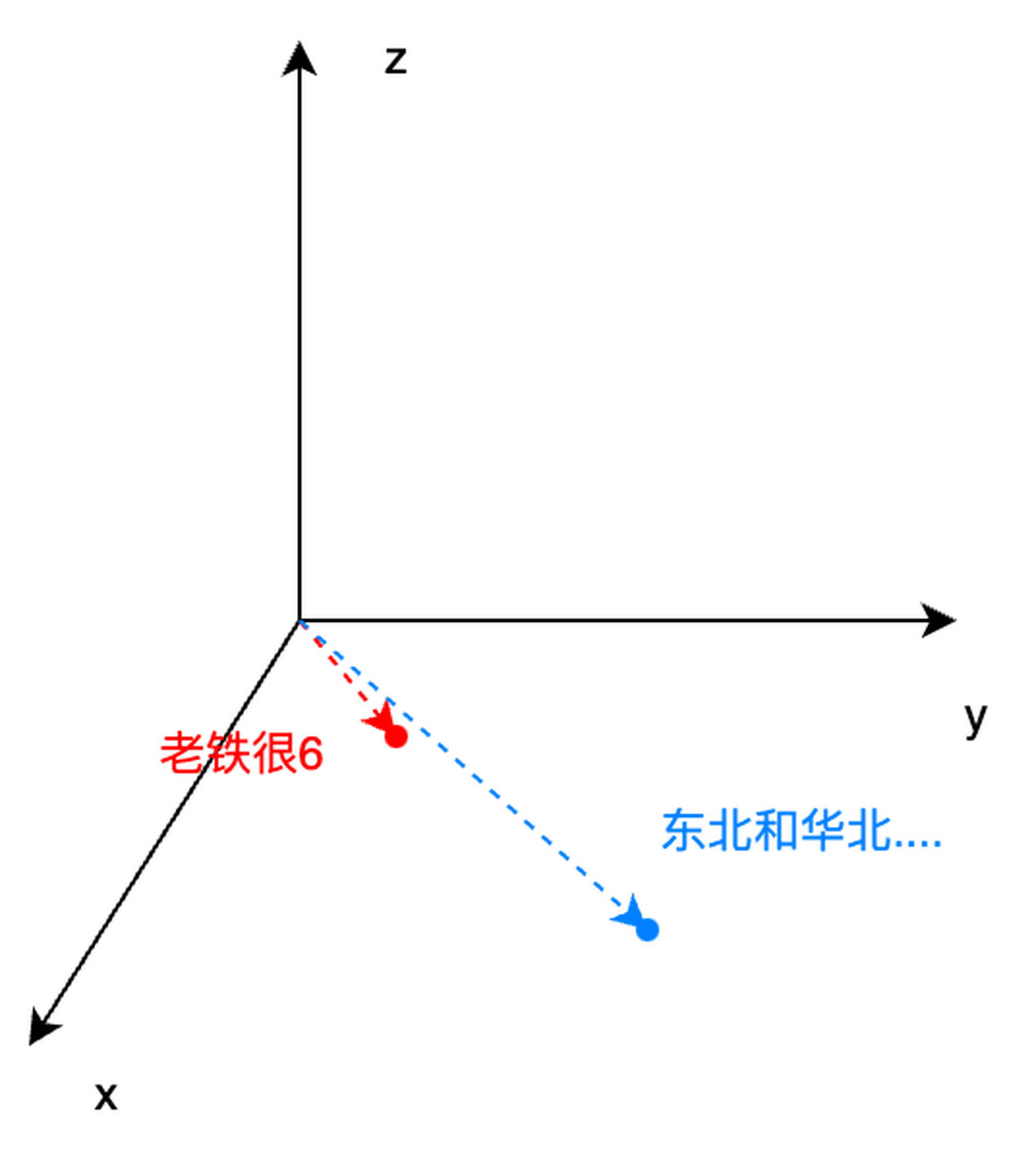
余弦相似度 (Cosine Similarity):衡量两个向量在向量空间中方向一致性的指标,广泛应用于自然语言处理(NLP)、推荐系统、图像检索等领域。它通过计算两个向量夹角的余弦值来反映它们的相似性,核心思想是忽略向量长度,关注方向差异
举个例子:
老铁很 6(坐标:[100,100,0])
东北和华北以及南部地区的老铁们,普遍反馈都很 6(坐标:[399,398,9])
通过计算 老铁很 6 和 东北和华北以及南部地区的老铁们,普遍反馈都很 6 这两句话在相似度上非常接近,因此搜索老铁很 6 的时候东北和华北以及南部地区的老铁们,普遍反馈都很 6 会被召回。
与其他相似度指标的对比 指标 公式 特点 适用场景 余弦相似度 (\frac{A \cdot B}{|A| |B|}) 忽略长度,关注方向;适合高维、长度不敏感场景 NLP、推荐系统、嵌入模型检索 欧氏距离 (\sqrt{\sum (a_i - b_i)^2}) 反映向量绝对距离;对长度敏感 低维稠密向量(如图像像素) 点积(Dot Product) (A \cdot B) 受向量长度影响大;未归一化时可能放大长向量的相似性 向量已归一化时等价于余弦相似度 曼哈顿距离 (\sum |a_i - b_i|) 对异常值敏感;计算效率高 路径规划、稀疏特征
3.2 索引: 快速检索与用户问题相关的知识库文档
索引构建使用的库 FAISS 和 Pinecone
特性 FAISS Pinecone 类型 开源库(Meta 开发) 托管服务(商业产品) 部署方式 本地部署,需自行管理 云端托管,无需基础设施维护 扩展性 需手动分片和扩展 自动水平扩展(根据负载动态调整) 持久化存储 需自行处理(如保存到磁盘) 内置持久化存储,自动备份 多租户支持 不支持 支持(企业级权限管理) 易用性 需要编码实现索引构建和查询 REST API/SDK 开箱即用 成本 免费 按用量付费(存储、查询次数) 适用场景 中小规模数据、本地 / 实验环境 大规模生产环境、需快速上线的项目
3.3 问答: 用户问题 –> 向量化 –> 向量索引 –> 检索 Top-K 相关文档 –> 输入 LLM 生成答案
简单的案例
实现从多段内容中,召回符合预期的内容 (faiss_example.py)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import faiss from sentence_transformers import SentenceTransformer # --- 1. 向量化 --- model = SentenceTransformer('all-MiniLM-L6-v2') texts = ["我们团队是一个比较厉害的技术团队", "都是爱吃肉的人,愿意一起吃肉", "科学家们都是爱学问的人"] # 创建一个字典来存储文档内容 document_dict = {i: doc for i, doc in enumerate(texts)} vectors = model.encode(texts).astype('float32') # 输出形状: (3, 384) # --- 2. 构建索引 --- dim = vectors.shape[1] index = faiss.IndexFlatL2(dim) # 精确搜索 index.add(vectors) # --- 3. 查询相似文档 --- def query_similar_documents(query): query_vector = model.encode([query]).astype('float32') # 向量化查询 k = 2 # 返回最相似的前k个文档 distances, indices = index.search(query_vector, k) print("最相似的索引:", indices[0]) # 输出: [1, 0] print("距离:", distances[0]) # 获取具体的文档内容 results = {index: document_dict[index] for index in indices[0]} print("相关文本:", results) # 测试查询 query_similar_documents("本地生活客户端")
三、本地问答知识库案例
要求: 支持上传 PDF、csv 等多种类型的文档
使用 streamlit 进行可视化界面操作
使用 deepseek-r1 模型进行问题
步骤:
本地下载 Ollama
1 2 3 4 # 直接点击Mac下载并安装 https://ollama.com/search# 直接点击Mac下载并安装 https://ollama.com/search# 直接点击Mac下载并安装 https://ollama.com/search下载deepseek-r1模型并运行
下载 deepseek-r1 模型并运行
1 2 3 4 # 下载 deepseek-r1模型,默认应该是7B,大了电脑也带不起来(4G左右) ollama pull deepseek-r1 # 使用ollama 启动deepseek-r1 (本地可以直接问题) ollama run deepseek-r1
需要下载的 Python 库
1 2 3 4 5 6 7 8 9 10 11 12 13 pip install openpyxl pip install -U langchain langchain-community pip install langchain pip install langchain_experimental pip install streamlit pip install pdfplumber pip install semantic-chunkers pip install open-text-embeddings pip install ollama pip install prompt-template pip install sentence-transformers pip install faiss pip install faiss-cpu
编写并启动文档能力(文档上传、向量化、索引、问题召回)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import streamlit as st from langchain_community.document_loaders import PDFPlumberLoader, CSVLoader from langchain_experimental.text_splitter import SemanticChunker from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.vectorstores import FAISS from langchain_community.llms import Ollama from langchain.prompts import PromptTemplate from langchain.chains.llm import LLMChain from langchain.chains.combine_documents.stuff import StuffDocumentsChain from langchain.chains import RetrievalQA # Color palette primary_color = "#1E90FF" secondary_color = "#FF6347" background_color = "#F5F5F5" text_color = "#4561e9" # Custom CSS st.markdown(f""" <style> .stApp {{ background-color: {background_color}; color: {text_color}; }} .stButton>button {{ background-color: {primary_color}; color: white; border-radius: 5px; border: none; padding: 10px 20px; font-size: 16px; }} .stTextInput>div>div>input {{ border: 2px solid {primary_color}; border-radius: 5px; padding: 10px; font-size: 16px; }} .stFileUploader>div>div>div>button {{ background-color: {secondary_color}; color: white; border-radius: 5px; border: none; padding: 10px 20px; font-size: 16px; }} </style> """, unsafe_allow_html=True) # Streamlit app title st.title("Build a RAG System with DeepSeek R1 & Ollama") # Initialize an empty list to store documents documents = [] # Load the files uploaded_files = st.file_uploader("Upload PDF or CSV files", type=["pdf", "csv"], accept_multiple_files=True) if uploaded_files: for uploaded_file in uploaded_files: # Save the uploaded file to a temporary location with open(uploaded_file.name, "wb") as f: f.write(uploaded_file.getvalue()) # Load the file based on its type if uploaded_file.type == "application/pdf": loader = PDFPlumberLoader(uploaded_file.name) docs = loader.load() elif uploaded_file.type == "text/csv": loader = CSVLoader(uploaded_file.name) # Load CSV files docs = loader.load() documents.extend(docs) # Add loaded documents to the list # Split into chunks only if documents are available if documents: text_splitter = SemanticChunker(HuggingFaceEmbeddings()) documents = text_splitter.split_documents(documents) # Instantiate the embedding model embedder = HuggingFaceEmbeddings() # Create the vector store and fill it with embeddings vector = FAISS.from_documents(documents, embedder) retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3}) # Define llm llm = Ollama(model="deepseek-r1") # Define the prompt for QA prompt = """ 1. Use the following pieces of context to answer the question at the end. 2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n 3. Keep the answer crisp and limited to 3,4 sentences. Context: {context} Question: {question} Helpful Answer:""" QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt) llm_chain = LLMChain( llm=llm, prompt=QA_CHAIN_PROMPT, callbacks=None, verbose=True) document_prompt = PromptTemplate( input_variables=["page_content", "source"], template="Context:\ncontent:{page_content}\nsource:{source}", ) combine_documents_chain = StuffDocumentsChain( llm_chain=llm_chain, document_variable_, document_prompt=document_prompt, callbacks=None) qa = RetrievalQA( combine_documents_chain=combine_documents_chain, verbose=True, retriever=retriever, return_source_documents=True) # User input user_input = st.text_input("Ask a question related to the uploaded documents:") # Process user input if user_input: with st.spinner("Processing..."): response = qa(user_input)["result"] st.write("Response:") st.write(response) else: st.write("Please upload PDF or CSV files to proceed.")
使用 streamlit 进行启动
成功后可以进行问答:
四、Query Translation 提高召回能力 我们不能指望所有的用户都能清楚地描述自己的 Query,如果用户写了一句模棱两可的 Query 或者是一个复杂的 Query,那么检索到的文档也将是模棱两可或者难以准确检索,进而导致 LLM 的回答就不准确
方案一:Re-written
Re-written 是指对原始查询进行语义重写,保持核心意思不变,但调整语言表述,使得问题更易被知识库或检索系统处理。
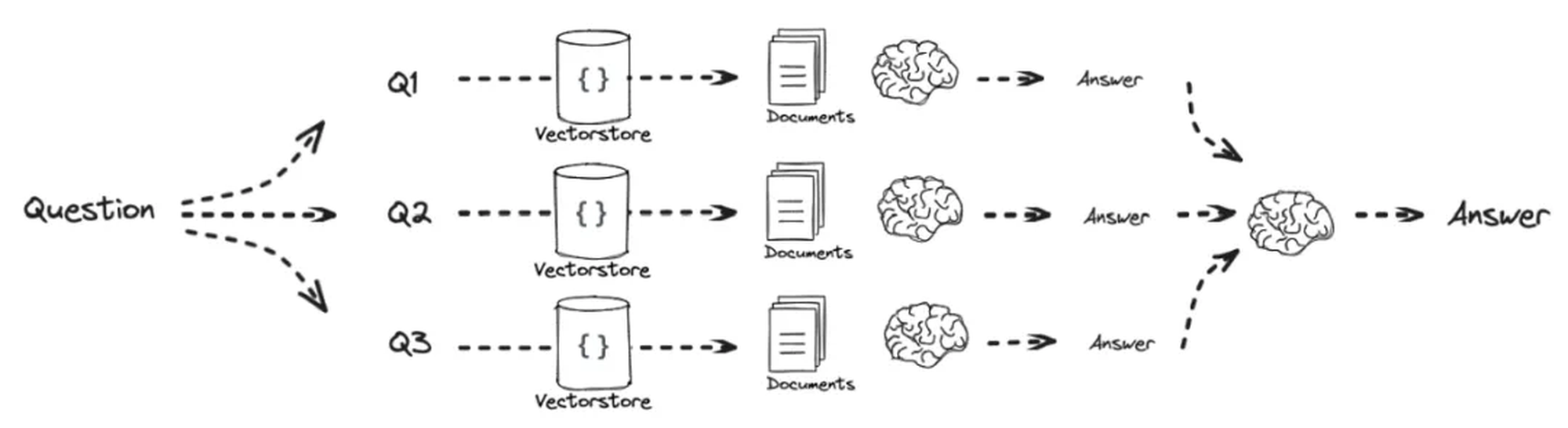
我们将原始 Question 改写成三种表述方式 Q1、Q2 和 Q3,然后分别检索与这三种问题相关的文档:
示例:本地生活是什么?
改写:
本地生活是一个行业,他主要运营方向是什么,根据美团、快手等本地生活业务,介绍本地生活是什么?
本地生活按照业务解释是什么?根据行业解读应该是什么样子?
…
(图片来源查询翻译 )
**方案二:Decomposition(**分解)
也就是 sub-question,是将复杂的问题拆解为多个独立的子问题,每个子问题可以单独处理。最终通过聚合子问题的答案来生成完整的回答。
应用场景:
多跳问题(需要跨多个知识点回答)。
包含逻辑操作或条件限制的问题。
示例:
原始问题:E14 和 E6 的职级区别是什么?
Sub-question:
E14 的职级要求是什么?
E6 的直接要求是什么?
根据召回的 E14 和 E6 的职级要求,生成两者之间的差别
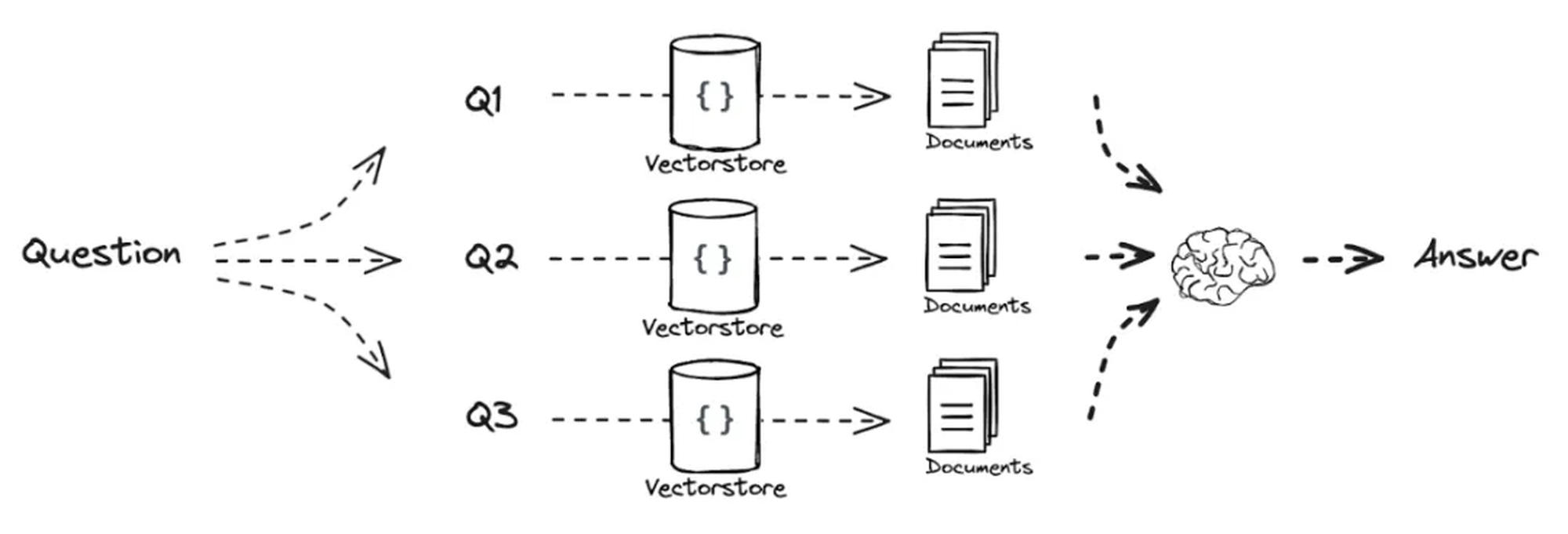
(串行拆分) (图片来源查询翻译 )
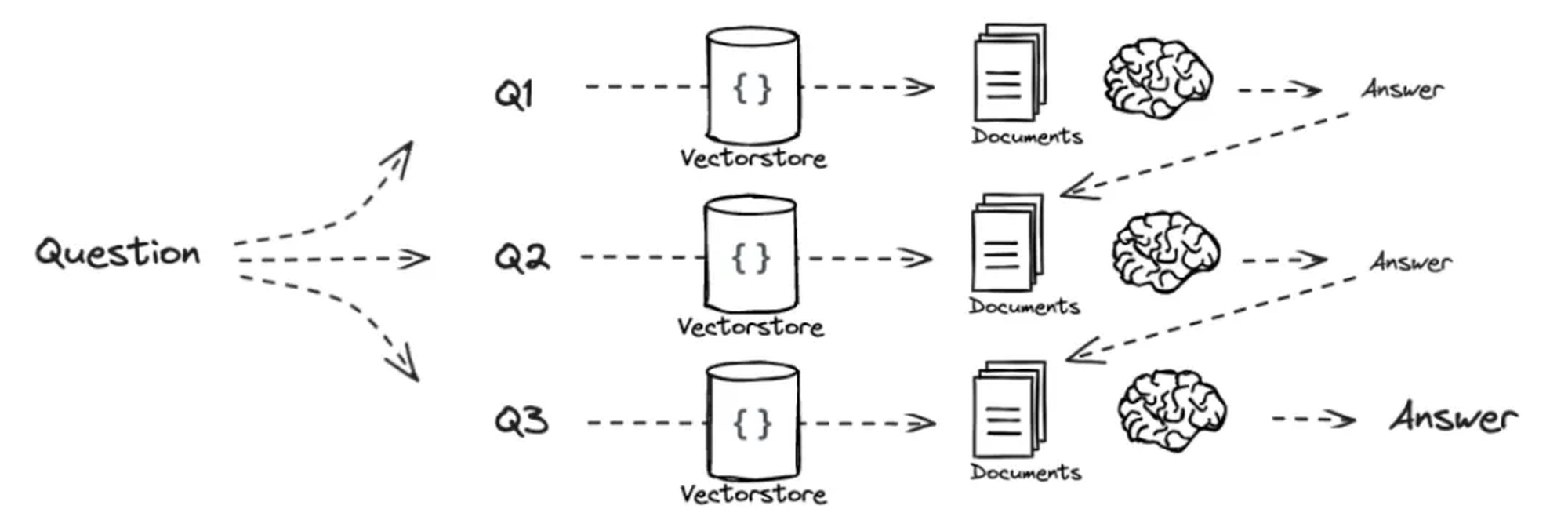
(并行拆分) (图片来源查询翻译 )
方案三:Step-back Question
在检索和回答过程中,当系统意识到当前的问题太具体或难以直接回答时,退一步改问一个更广泛、更概括性的问题,从而获取更大的上下文信息。
第一步:抽象(Abstraction):在这一步,问题的基础原理和概念先被提取出来。例如,面对理化问题,先问 “解决这个任务涉及哪些物理或化学原理和概念?”,从而让模型先确定这些原理和概念。
第二步:推理(Reasoning):有了基础原理后,再进行问题的解答。例如,根据气体定律来计算压力如何变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 原题:如果一辆汽车以100公里/小时的速度行驶,行驶200公里,需要多长时间? 选项: 1.4小时 2.2小时 3.1小时 4.3小时 原答案[不正确]:正确答案是4)3小时。 后退提示:给定速度和距离,计算时间的基本公式是什么? 原则:为了计算时间,我们使用以下公式:时间=距离/速度 使用公式,时间=200公里/100公里/小时=2小时。 修正后答案[正确]:正确答案是2)2小时。
方案四:HyDE(Hypothetical Document Embedding)(基于假设)
根据问答,生成一个假设性回答,再拿着假设性答案,再次去搜索文档。
通过假设性文档生成和后续的向量相比,HyDE 能够捕捉查询深层意图和复杂内容,不仅限于关键词匹配。
示例:
1 2 3 4 5 当我们搜索“感冒的治疗手段” 这个时候通过RAG召回的信息有限。 先生成假设性答案: 包含治疗手段、药物治疗、物理治疗、手术治疗、不同医院治疗方案等(即便这些信息在文档实际数据中并不存在),然后寻找与假设文档相似的实际文档。
五、当前比较流行的 RAG 概念还有哪些
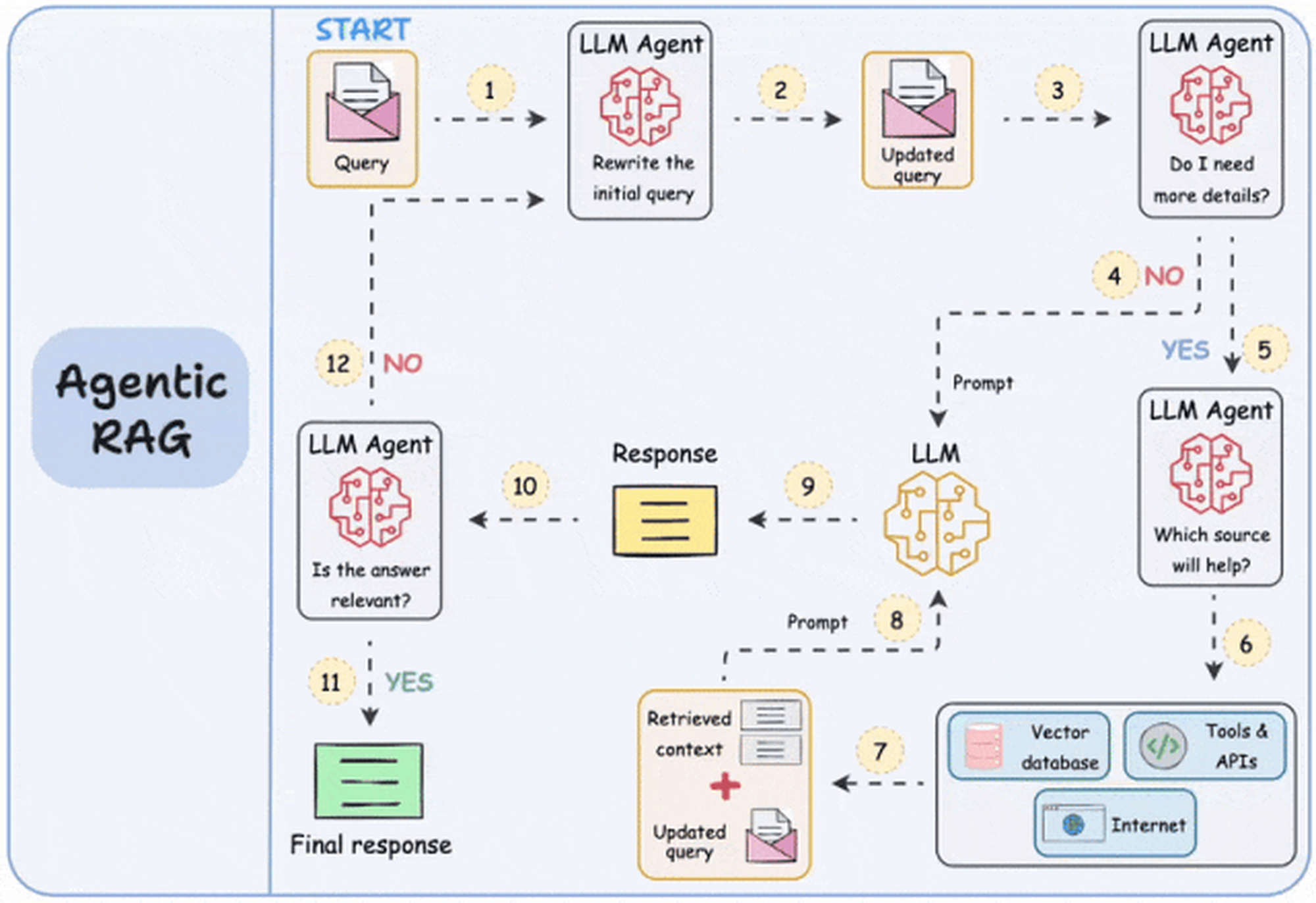
Agentic RAG
(图片来源传统 RAG vs. Agentic RAG:动态图示清晰解析 )
资料、文档嵌入
问题嵌入,并进行知识库搜索
将问题和搜索的内容,一并提交给大模型生成答案
(图片来源传统 RAG vs. Agentic RAG:动态图示清晰解析 )
第 1-2 步)Agent 会重写查询(如纠正拼写错误等)。
第 3-8 步)Agent 决定是否需要更多上下文信息:
如果不需要,重写后的查询直接发送给 LLM。
如果需要,智能代理会找到最佳的外部来源以获取上下文,并将其传递给 LLM。
第 9 步)系统生成响应。
第 10-12 步)智能代理检查答案是否相关:
如果相关,则返回响应。
如果不相关,则返回第 1 步重新开始。